
Al analizar lo que se necesita para construir e implementar un modelo de lenguaje grande, se revela qué actores tienen más posibilidades de ganar y dónde los nuevos participantes podrían tener mejores perspectivas.
En los meses transcurridos desde el lanzamiento público de ChatGPT, se han realizado inversiones masivas en empresas emergentes de IA generativa. El entusiasmo es merecido. Los primeros estudios han demostrado que esta tecnología puede generar aumentos significativos en la productividad.1
Algunos de esos aumentos provendrán de aumentar el esfuerzo humano y otros de sustituirlo.
Pero las preguntas que quedan por responder son: ¿quién captará el valor de este mercado en expansión y cuáles son los determinantes de la captura de valor?
Para responder a estas preguntas, analizamos la pila de IA generativa e identificamos los puntos propicios para la diferenciación. Si bien existen modelos de IA generativa para texto, imágenes, audio y video, utilizamos el texto (LLM) como contexto ilustrativo para nuestro análisis a lo largo del artículo.
Reinventa tu negocio para recibir de forma apropiada la IA generativa y los LLM
Infraestructura informática
En la base de la pila de IA generativa se encuentra una infraestructura informática especializada impulsada por unidades de procesamiento gráfico (GPU) de alto rendimiento.
Para crear un nuevo modelo o servicio de IA generativa, una empresa podría considerar la posibilidad de comprar GPU y hardware relacionado. Esto para configurar la infraestructura necesaria para entrenar y ejecutar un LLM localmente.
Sin embargo, esto probablemente sería prohibitivo en términos de costos. Esto debido a que esta infraestructura suele estar disponible a través de los principales proveedores de la nube, incluidos Amazon Web Services (AWS), Google Cloud y Microsoft Azure.
Datos
Los modelos de IA generativa se entrenan con datos masivos a escala de Internet. Por ejemplo, los datos de entrenamiento para GPT-3 de OpenAI incluyeron Common Crawl, un repositorio de datos de rastreo web disponible públicamente, así como Wikipedia, libros en línea y otras fuentes.
El uso de conjuntos de datos como Common Crawl implica que se ingirieron datos de muchos sitios web, como los del New York Times y Reddit, durante el proceso de entrenamiento.
Además, los modelos básicos también incluyen datos específicos del dominio que se rastrean desde la web, se obtienen bajo licencia de socio. También se pueden comprar en mercados de datos como Snowflake Marketplace.
Si bien los desarrolladores de modelos de IA explican cómo se entrenó el modelo, no brindan información sobre la procedencia de sus datos de entrenamiento. Aun así, los investigadores han podido usar técnicas como ataques de inyección rápida para revelar las diferentes fuentes de datos utilizadas para entrenar la IA.
Modelos de base
Los modelos de base son redes neuronales ampliamente entrenadas en conjuntos de datos masivos sin estar optimizadas para dominios específicos. Los modelos de lenguaje de base incluyen modelos de código cerrado como GPT-4 de OpenAI, así como modelos de código abierto como Llama-2 de Meta.
Todos estos modelos se basan en la arquitectura de transformadores descrita en un artículo seminal de 2017 de Vaswani et al.2 Si bien uno podría intentar ingresar a la pila de IA generativa mediante la creación de un nuevo modelo de base, los datos, los recursos informáticos y la experiencia técnica necesarios para crear y entrenar modelos de alto rendimiento forman una barrera de entrada significativa.
RAG y modelos ajustados
Los modelos básicos son versátiles y tienen un buen rendimiento para una amplia gama de tareas lingüísticas. Pero es posible que no tengan el mejor rendimiento para contextos y tareas específicos.
Para tener un buen rendimiento en tareas específicas del contexto, es posible que haya que incorporar datos específicos del dominio. Un servicio que tiene como objetivo utilizar un LLM para un propósito específico, como ayudar a los usuarios a solucionar problemas técnicos con un producto, podría adoptar uno de dos enfoques.
El primero implica la creación de un servicio que recupera fragmentos de información relevantes para la pregunta del usuario final y agrega la información a la instrucción (aviso) enviada al modelo básico.
En nuestro ejemplo de ayudar a los usuarios a solucionar problemas. Esto implica escribir código que extraiga el material pertinente del manual del producto que esté más relacionado con la pregunta del usuario final. Además, de dar instrucciones al LLM para que responda la pregunta del usuario basándose en ese fragmento de información.
Este enfoque se denomina generación aumentada por recuperación (RAG). Los modelos básicos tienen límites en cuanto al tamaño de las indicaciones que pueden aceptar. Pero pueden tener hasta aproximadamente 100 mil palabras.
Los gastos en los que se incurre con este enfoque incluyen los costos de API del modelo básico, que aumentan en función del tamaño de la indicación de entrada y del tamaño de la salida del LLM. Como resultado, cuanta más información de los manuales de productos se envíe al LLM, mayor será el costo de su uso.
Cuál ha sido rol de la IA Generativa en la innovación y flexibilidad empresarial
Aplicaciones LLM
La capa final de la pila consta de aplicaciones que se pueden crear sobre la base o el modelo ajustado para servir a un caso de uso específico. Las empresas emergentes han creado aplicaciones para redactar contratos legales, resumir libros y guiones de películas.
Estas aplicaciones tienen un precio similar al de las aplicaciones tradicionales de software como servicio y sus costos marginales están principalmente vinculados a las tarifas de alojamiento de aplicaciones en la nube y las tarifas de API de los modelos básicos.
En los últimos meses, los gigantes tecnológicos y los inversionistas de riesgo han realizado inversiones masivas en cada capa de esta pila. Se han lanzado docenas de nuevos modelos básicos.3
De manera similar, las empresas han creado modelos específicos para cada tarea, perfeccionados con datos de su propiedad. Esto con la esperanza de que les den una ventaja sobre sus competidores. Y miles de empresas emergentes están creando aplicaciones sobre la base de varios modelos básicos o perfeccionados.
IA generativa, lecciones de la nube
¿Qué actores se beneficiarán más de estas inversiones? En los últimos meses se han lanzado decenas de modelos básicos. Muchos de estos pueden ofrecer un rendimiento comparable al de los modelos básicos más populares.
Sin embargo, creemos que el mercado de los modelos básicos bien podría consolidarse entre unos pocos actores. De la misma manera que la mayor parte de la cuota de mercado (y el valor) de los servicios en la nube ha quedado en manos de empresas como Amazon, Google y Microsoft.
Hay tres razones por las que la mayoría de las empresas emergentes de infraestructura en la nube fracasaron. Estas también se aplican a la IA generativa.
El costo y la capacidad necesarias para crear una IA son muy altos
La primera es el costo y la capacidad necesarios para crear, mantener y mejorar una infraestructura técnica de alta calidad. Esto se agrava aún más en el caso de los LLM e incluye el costo de las GPU, que escasean en relación con su demanda.
El costo computacional de la ejecución de entrenamiento final del modelo PaLM de 540 mil millones de parámetros de Google solo fue de entre 9 millones y 23 millones de dólares, según una estimación externa.
De manera similar, se estima que las inversiones de Meta en GPU en 2023 y 2024 serán de más de $ 9 mil millones. Además, construir un modelo de base requiere acceso a cantidades masivas de datos, así como una experimentación y experiencia significativas.
Los efectos de red del lado de la demanda
El segundo son los efectos de red del lado de la demanda. A medida que crezca el ecosistema en torno a estas infraestructuras, también lo harán las barreras para nuevos participantes en el mercado.
Tomemos como ejemplo PromptBase, un mercado en línea de sugerencias para incorporar a los LLM. La mayor cantidad de sugerencias que se ofrecen son para ChatGPT y los populares generadores de imágenes Dall-E, Midjourney y Stable Diffusion.
Una nueva LLM puede ser atractiva desde un punto de vista tecnológico, pero si los usuarios tienen una gran cantidad de sugerencias que funcionan bien en ChatGPT y ninguna sugerencia probada para la nueva LLM, es probable que se queden con ChatGPT.
Si bien las arquitecturas subyacentes son similares en todas las LLM, están muy diseñadas y las estrategias de sugerencias que funcionan bien con una LLM pueden no funcionar tan bien con otras.
Economías de escala
Un tercer factor son las economías de escala. Los beneficios del lado de la oferta que ofrece la agrupación de recursos y la agregación de la demanda permitirán que los LLM con grandes bases de clientes tengan un costo por consulta menor que los LLM de nueva creación.
Estos beneficios incluyen la posibilidad de negociar mejores tarifas con los proveedores de GPU y los proveedores de servicios en la nube.
Por las razones expuestas, si bien periódicamente se lanzan nuevos modelos de base, esperamos que este mercado se consolide en torno a unos pocos actores.
¿Construir o pedir prestado para generar IA?
Las empresas que quieran entrar en el mercado de servicios de IA generativa tendrán que decidir si crear aplicaciones sobre modelos de base de terceros. La creación de modelos de terceros puede conllevar riesgos de seguridad, como la posible exposición de datos privados.
Este riesgo se mitiga en parte mediante el uso de proveedores de nube y LLM de confianza que puedan garantizar que los datos de los clientes permanezcan confidenciales y no se utilicen para entrenar y mejorar sus modelos.
Una alternativa es aprovechar los modelos LLM de código abierto sin depender de proveedores externos como OpenAI. El atractivo de los modelos de código abierto es que brindan a las empresas un acceso completo y transparente al modelo, suelen ser más económicos y pueden alojarse en nubes privadas.
Sin embargo, los modelos de código abierto actualmente están por detrás de GPT-4 en términos de rendimiento en tareas complejas. Además, alojar dichos modelos requiere habilidades y conocimientos técnicos internos, Mientras tanto, usar un LLM alojado por un tercero puede ser tan simple como registrarse en un servicio y usar las API del proveedor.
Los proveedores de la nube han comenzado cada vez más a alojar modelos de código abierto y a ofrecer acceso a ellos a través de una API.
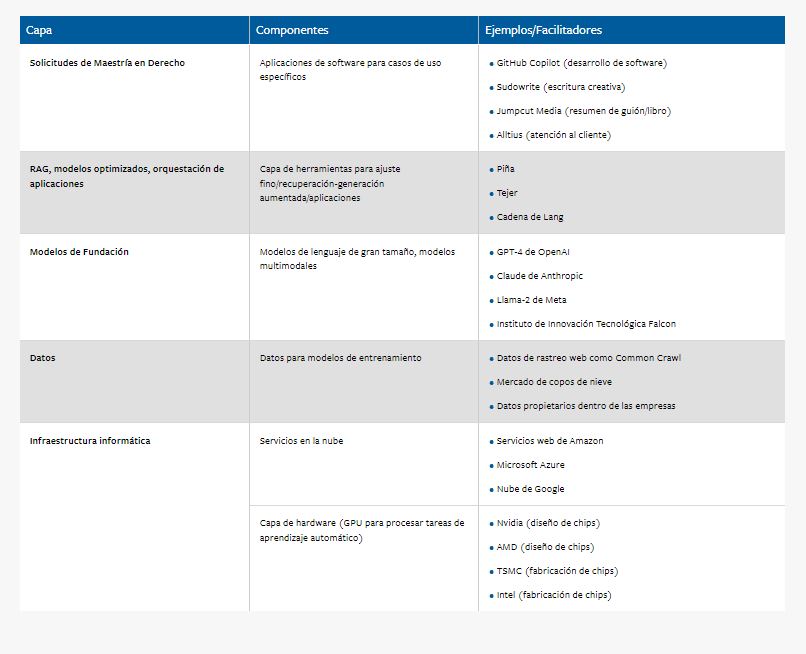
Estos son los componentes que forman las capas de valor en la industria de la IA generativa.
La IA generativa ha revolucionado la creación y el escalado de la publicidad digital
Oportunidades específicas del dominio
El rendimiento de un LLM está determinado por la arquitectura de la red neuronal (el modelo) y la cantidad y calidad de los datos con los que se entrena.
Los modelos de transformación requieren grandes cantidades de datos. Los modelos de transformación de alto rendimiento operan en una escala de más de un billón de tokens de datos de Internet y miles de millones de parámetros.
Los LLM más grandes tienen el mejor rendimiento en una amplia variedad de tareas. Pero la calidad y la singularidad de los datos pueden ser igualmente importantes para la eficacia de los LLM.
Los modelos entrenados o ajustados con datos específicos del dominio pueden superar a los modelos de propósito general más grandes. Por esta razón, las organizaciones que tienen acceso a grandes volúmenes de datos de alta calidad en dominios específicos pueden tener una ventaja sobre otros actores.
Por ejemplo, Bloomberg aprovechó su acceso a datos financieros para construir un modelo especializado en tareas financieras. BloombergGPT es un modelo de 50 mil millones de parámetros, en comparación con los aproximadamente 475 mil millones de parámetros de ChatGPT-3.5.
Sin embargo, las primeras investigaciones mostraron que superaba a ChatGPT-3.5 en una serie de tareas financieras de referencia.4 Ambos modelos se entrenan en grandes conjuntos de datos: BloombergGPT se entrena en 700 mil millones de tokens y ChatGPT-3.5 en 500 mil millones.
Pero más del 52 por ciento del conjunto de datos de entrenamiento de BloombergGPT consiste en fuentes financieras seleccionadas. Esto le da una ventaja en tareas específicas del dominio. Dicho esto, un estudio reciente mostró que GPT-4, con indicaciones mejoradas, superaba a BloombergGPT en tareas financieras simples, como el análisis de sentimientos.5
Atribuimos esto al mayor tamaño del modelo de GPT-4. En resumen, si bien los modelos creados con datos específicos del dominio pueden ofrecer un rendimiento sólido con modelos más pequeños.
La importancia de la interfaz de usuario en el uso de la IA
Las empresas que crean aplicaciones sobre modelos de base se enfrentan al dilema de que los competidores pueden replicar fácilmente su funcionalidad A falta de una diferenciación basada en modelos o datos, las empresas tendrán que distinguirse al final del proceso. La interfaz donde la inteligencia de las máquinas se encuentra con el usuario.
Las empresas tecnológicas tradicionales tendrán una inclinación natural hacia la integración vertical, en la que el creador de LLM también sea propietario de la aplicación. Google ya está integrando sus capacidades LLM en Google Docs y Gmail, al igual que Microsoft lo está haciendo es asociación con OpenAI.
Al mismo tiempo, las empresas que no cuentan con sus propias LLM pueden tener éxito creando aplicaciones adaptadas a su base de usuarios existente. Pueden aprovechar su acceso de última milla para agrupar fácilmente nuevas capacidades habilitadas para IA en sus ofertas existentes.
En otras palabras, si existe un mercado grande y competitivo de LLM que ofrecen características aproximadamente equivalentes. Esta ventaja, junto con las ventajas de datos que ya poseen las empresas ya establecidas, plantea desafíos para los nuevos participantes.
¿Cuáles son las implicaciones para los gerentes que están formulando sus estrategias de IA generativa? Si su empresa es una de las que ya tiene presencia en su sector, deben pensar seriamente en qué tareas complejas específicas de cada dominio se pueden abordar mejor utilizando datos patentados.
Esta ventaja patentada permitirá a una empresa ofrecer un valor único a sus clientes.
Los derechos de autor
Una amplia variedad de creadores de contenido han expresado su preocupación por los derechos de autor y la propiedad intelectual que se utilizan para entrenar a los LLM.
El New York Times ha presentado una demanda contra OpenAI alegando que utilizó el contenido del Times para entrenar a sus modelos. Otras empresas, autores y programadores también han presentado demandas contra los propietarios de LLM por razones similares.
Si bien OpenAI ha argumentado que entrenar a los modelos con contenido protegido por derechos de autor, también ha reconocido la necesidad de establecer nuevos modelos de acuerdo de uso de contenido y ha firmado un acuerdo con la empresa de medios Axel Springer para utilizar su contenido para entrenar a los modelos de OpenAI.
Independientemente de cómo se resuelvan estas demandas, es probable que las preocupaciones subyacentes en torno al entrenamiento de modelos sobre propiedad intelectual creada por otras partes resulten en una mayor ventaja para los actores establecidos en la IA generativa.
A diferencia de entidades más pequeñas o más nuevas, empresas como Google, Microsoft y Meta tienen los recursos para luchar contra demandas de derechos de autor.
Permanecer juntos o permanecer solos
¿Qué significa esto para las empresas que ofrecen productos y servicios de IA generativa? Aquellas que buscan crear un nuevo modelo de base podrían tener dificultades para competir en el rendimiento del modelo con los actores existentes.
La forma de competir más allá del rendimiento del modelo es desarrollar el ecosistema. Por ejemplo, las herramientas para cada capa de la pila, como aquellas que faciliten especialmente a un desarrollador de aplicaciones ajustar o aplicar RAG sobre un modelo de base.
Si una organización tiene datos específicos de dominio a gran escala, un LLM específico de dominio le permitirá diferenciarse de los modelos de propósito general.
Las empresas que buscan experimentar con la IA generativa deben aclarar rápidamente los casos de uso. Algunos de los criterios relevantes se basan en las respuestas a tres preguntas:
- ¿El caso de uso no está regulado?
- ¿Se pueden controlar los errores?
- ¿Tiene datos exclusivos y conocimiento del dominio para habilitar y controlar el ajuste fino o RAG?
SOBRE LOS AUTORES
Kartik Hosanagar es profesor de Tecnología y Negocios Digitales John C. Hower en la Wharton School de la Universidad de Pensilvania. Ramayya Krishnan es decano de la Facultad Heinz de Sistemas de Información y Políticas Públicas de la Universidad Carnegie Mellon.
REFERENCIAS (5)
1. S. Peng, E. Kalliamvakou, P. Cihon, et al., “El impacto de la IA en la productividad de los desarrolladores: evidencia de GitHub Copilot”, arXiv, enviado el 13 de febrero de 2023, https://arxiv.org; y S. Noy y W. Zhang, “ Evidencia experimental sobre los efectos de la inteligencia artificial generativa en la productividad ”, Science 381, n.º 6654 (13 de julio de 2023): 187-192.
2. A. Vaswani, N. Shazeer, N. Parmar, et al., “Attention Is All You Need” (artículo presentado en la 31.ª Conferencia Anual sobre Sistemas de Procesamiento de Información Neural, Long Beach, California, 6 de diciembre de 2017).
3. Para un catálogo de algunos de estos modelos, véase X. Amatriain, A. Sankar, J. Bing, et al., “Transformer Models: An Introduction and Catalog”, arXiv, revisado el 25 de mayo de 2023, https://arxiv.org.
4. S. Wu, O. Irsoy, S. Lu, et al., “BloombergGPT: un modelo de lenguaje grande para finanzas“, arXiv, revisado el 21 de diciembre de 2023, https://arxiv.org.
5. X. Li, S. Chan, X. Zhu, et al. “ ¿Son ChatGPT y GPT-4 solucionadores de propósito general para análisis de texto financiero? Un estudio sobre varias tareas típicas ”, arXiv, revisado el 10 de octubre de 2023, https://arxiv.org.
Te recomendamos Síguenos en Google News
Síguenos en Google News


Kartik Hosanagar y Ramayya Krishnan
Kartik Hosanagar es profesor de Tecnología y Negocios Digitales John C. Hower en la Wharton School de la Universidad de Pensilvania y director fundador del centro de IA de Wharton. Es autor de A Human's Guide to Machine Intelligence: How Algorithms Are Shaping Our Lives and How We Can Stay in Control (Viking, 2019) y del boletín Creative Intelligence . Ramayya Krishnan es decano de la Facultad Heinz de Sistemas de Información y Políticas Públicas de la Universidad Carnegie Mellon, donde también es profesor William W. Cooper y Ruth F. Cooper de Ciencias de la Gestión y Sistemas de Información. Es director fundador del Centro Block de Tecnología y Sociedad de la universidad y también preside el grupo de futuros de IA del comité asesor nacional de IA.y recibe contenido exclusivo
