
Los líderes empresariales deben tomar las decisiones correctas sobre si implementar modelos de IA y con qué amplitud. Haga estas preguntas difíciles.
El poder de la Inteligencia Artificial (IA) y los modelos de aprendizaje automático en los que se basa continúan remodelando las reglas de los negocios. Sin embargo, demasiados proyectos de IA están fracasando, a menudo después de su implementación. Esto que resulta especialmente costoso y vergonzoso.
Pregúntale a Amazon sobre sus fiascos en el reconocimiento facial , o a Microsoft sobre sus errores con su chatbot Tay .
Con demasiada frecuencia, los científicos de datos descartan tales fallas como anomalías individuales sin buscar patrones que puedan ayudar a prevenir fallas futuras.
Los altos directivos empresariales de hoy tienen el poder (y la responsabilidad) de evitar fallos posteriores a la implementación. Pero para hacerlo, deben comprender más sobre los conjuntos de datos y los modelos de datos para poder hacer las preguntas correctas a los desarrolladores de modelos de IA y evaluar las respuestas.
Cómo usar a tu favor el análisis de datos basado en decisiones y hacer crecer a tu empresa
Quizás pienses: “¿Pero no están los científicos de datos e IA altamente capacitados?”
La gran mayoría de la formación de los científicos de datos actuales se centra en la mecánica del aprendizaje automático, no en sus limitaciones. Esto los deja mal equipados para prevenir o diagnosticar adecuadamente las fallas del modelo de IA.
Los desarrolladores deben evaluar la capacidad de un modelo para funcionar en el futuro y más allá de los límites de sus conjuntos de datos de entrenamiento. A este concepto que llaman generalización . Hoy este concepto está mal definido y carece de rigor.
Un dicho en análisis afirma que los desarrolladores de modelos y los artistas comparten el mismo mal hábito de enamorarse de sus modelos.
Los datos, por otro lado, no reciben la atención que requieren. Por ejemplo, es muy fácil para los desarrolladores de modelos de IA conformarse con conjuntos de datos fácilmente disponibles en lugar de buscar otros más adecuados para el problema en cuestión.
Los altos directivos de empresas, que carecen de títulos avanzados en disciplinas técnicas, están aún menos preparados para detectar problemas en la IA.
Sin embargo, son estos líderes empresariales quienes en última instancia deciden si implementar modelos de IA y con qué amplitud.
¿Qué pueden hacer los líderes ante la IA?
- Un marco que ofrece el contexto necesario. En particular, introduciremos el concepto de “los datos correctos“. Las discrepancias entre los datos correctos y los datos realmente empleados en un proyecto de IA pueden ser riesgosas
- Un conjunto de seis preguntas para hacer a los desarrolladores de modelos de IA de su organización antes y durante el trabajo
- Orientación sobre cómo evaluar las respuestas de los desarrolladores de modelos de IA a esas seis preguntas.
Cómo identificar los datos correctos: La biblia de la IA
El éxito o el fracaso de un proyecto de IA depende del conjunto de datos que utiliza. Para ayudar a los equipos a obtener los datos correctos, ofrecemos un marco de cinco elementos que se describe a continuación. Vamos a dividirlo en sus componentes.
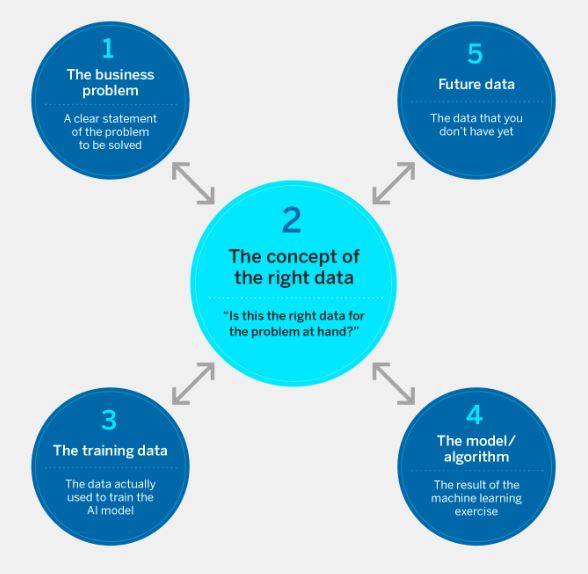
¿Ese proyecto de IA está destinado a tener éxito? Este marco le ayudará a tener debates más informados con los desarrolladores de modelos de IA. Una vez que haya confirmado el problema empresarial que desea resolver, identificar los datos correctos es fundamental, como se muestra aquí. Sin el conjunto de datos adecuado, su proyecto de IA fracasará. Pero también necesitarás evaluar las piezas relacionadas: los datos de entrenamiento, el modelo de IA y los datos que se aplicarán al modelo en el futuro.
Análisis de datos, el gran superpoder para reclutar nuevo talento para la organización
1. El problema y la población de interés
Toda buena ciencia de datos requiere un planteamiento claro del problema a resolver.
Por muy obvio que parezca, descubrimos que los desarrolladores de modelos de IA a menudo no han pensado lo suficiente en esto o que los miembros del equipo tienen diferentes interpretaciones del problema que están tratando de resolver.
Por ejemplo, ¿cuál es nuestro objetivo comercial final en relación con un nuevo modelo automatizado de calificación crediticia? ¿Es para ahorrar tiempo?
¿Se trata de reemplazar a los aseguradores o simplemente de asesorarlos? ¿El objetivo es cometer menos errores crediticios o reducir el sesgo?
La respuesta podría implicar alguna combinación de esos objetivos. Un detalle más: ¿debe la lógica ser explicable para las personas a las que se les rechaza el crédito, o serán suficientes los modelos de caja negra?
Las respuestas a estas preguntas sobre problemas empresariales conducirán a diferentes soluciones.
2. El concepto de datos correctos
Una contribución clave a los fundamentos de la calidad de los datos ha sido el concepto de idoneidad para el uso. Si un determinado conjunto de datos es apropiado o apto para una determinada decisión, operación o análisis.
Dependiendo del problema, puede haber muchos y variados aspectos de idoneidad para el uso, pero dos: “¿Son correctos los datos?” y “¿Son estos los datos correctos?” – siempre son importantes.
Aquí nos centraremos en la pregunta “¿Son estos los datos correctos?” porque es fundamental para evaluar la generalización y prevenir el fracaso del proyecto.
Los criterios en los que se deben de centrar los líderes
Para responder a esta pregunta, los gerentes deben centrarse en seis criterios:
1. Relevancia/integridad
Los datos deben tener poder predictivo. En nuestro ejemplo de calificación crediticia, atributos como la edad, el historial de pagos atrasados y los ingresos podrían contribuir. Idealmente, se incluyen todos esos atributos y se excluyen todos los atributos engañosos, superfluos o ilegales
2. Integralidad/representación adecuada
Las dos cuestiones principales son “¿Cubren los datos adecuadamente a la población de interés?” y “¿Hay suficiente para entrenar adecuadamente el modelo?” Es importante destacar que la privacidad u otras preocupaciones pueden dictar que ciertos datos deban excluirse
3. Ausencia de sesgos
Muchos tipos de sesgos pueden estar ocultos en los datos, y esta dimensión exige su eliminación. Esta es una preocupación especial en nuestro ejemplo de calificación crediticia y siempre que el problema de interés involucra a seres humanos
6. Oportunidad
La cuestión esencial es “¿Qué tan nuevos deben ser los datos?” Para algunos problemas, los datos más antiguos pueden contener sesgos que son difíciles de eliminar.
Y en algunas aplicaciones, los datos (futuros) ya no son relevantes apenas unos segundos después de haber sido creados.
7, Definición clara
Todos los términos, incluidas las unidades de medida , deben definirse claramente.
8. Exclusiones apropiadas
En las discusiones anteriores sobre relevancia y exhaustividad, observamos que algunos datos deben excluirse, dadas consideraciones legales, regulatorias, éticas y de propiedad intelectual.
Por ejemplo, el uso de códigos postales puede ser un sustituto de la raza en las decisiones crediticias, y las organizaciones deben evitar violar las leyes que estipulan cómo se puede utilizar la información de identificación personal.
Existe una creciente preocupación de que los modelos de IA entrenados con fuentes públicas puedan violar los derechos de propiedad intelectual. Los gerentes, o los equipos legales de sus empresas, deben explicar los requisitos lo más detalladamente posible.
Guía ejecutiva para no morir en el intento durante la era del análisis de datos
3. Los datos de entrenamiento para la IA
Esto se refiere a los datos realmente utilizados para entrenar el modelo, independientemente de si son, de hecho, los datos correctos.
4. El modelo/algoritmo
Este es el resultado del ejercicio de aprendizaje automático. Una vez entrenado, el modelo se puede actualizar en el futuro utilizando nuevos datos. Esto se conoce comúnmente como “datos futuros”.
5. Datos futuros
Esto se refiere a datos que aún no tiene pero que se aplicarán al modelo de IA en el futuro.
¿Qué son los datos correctos para la IA?
Como se muestra en la figura, el concepto de datos correctos es fundamental para todo. Lo llamamos el concepto de datos correctos porque a menudo se trata de los criterios que uno espera que satisfagan los datos que de un conjunto de datos real.
Los desarrolladores de modelos primero deben aclarar el problema y la población de interés. A continuación, deben definir los criterios que deben cumplir los datos utilizados para entrenar el modelo para abordar ese problema.
En tercer lugar, deberían comparar los datos de formación que realmente pueden obtener con estos criterios. Entonces deberían hacer comparaciones similares con datos futuros. Las brechas o desajustes cada vez más grandes indican problemas.
Como señalamos anteriormente, es fácil para los desarrolladores enamorarse de los modelos que han creado, y los datos que se obtienen fácilmente y los que mejor se adaptan al problema empresarial pueden ser bastante diferentes.
Para evitar problemas, los líderes empresariales deben guiar al equipo a través de una consideración fría y sobria de los datos correctos. Esta es la mejor defensa contra el entusiasmo excesivo, la absoluta arrogancia de los modelos y los vergonzosos fracasos de los proyectos de IA.
SOBRE LOS AUTORES
Roger W. Hoerl es profesor Brate-Peschel de Estadística en Union College en Schenectady, Nueva York, y coautor con Ronald D. Snee de Leading Holistic Improvement With Lean Six Sigma 2.0 , 2ª ed. (Pearson FT Press, 2018). Thomas C. Redman es presidente de Data Quality Solutions y autor de People and Data: Uniting to Transform Your Organization (KoganPage, 2023).
Te recomendamos Síguenos en Google News
Síguenos en Google News



Roger W. Hoerl y Thomas C. Redman
Roger W. Hoerl es profesor Brate-Peschel de Estadística en Union College en Schenectady, Nueva York, y coautor con Ronald D. Snee de Leading Holistic Improvement With Lean Six Sigma 2.0 , 2ª ed. (Pearson FT Press, 2018). Thomas C. Redman es presidente de Data Quality Solutions y autor de People and Data: Uniting to Transform Your Organization (KoganPage, 2023).y recibe contenido exclusivo
