
Un nuevo enfoque para entrenar modelos de IA permite a las empresas con pequeños conjuntos de datos colaborar y salvaguardar la información privada.
El acceso al talento y las enormes inversiones en infraestructura solo se explican en parte porque la mayoría de los avances en Inteligencia Artificial (IA) proceden de un selecto grupo de grandes empresas. Por ejemplo: Amazon, Google y Microsoft.
Lo que distingue a los gigantes tecnológicos de las muchas otras empresas que tratan de obtener una ventaja de la IA son las enormes cantidades de datos que recopilan. Solo Amazon procesa millones de transacciones al mes en su plataforma.
Todos esos macrodatos son un recurso estratégico de gran riqueza que puede utilizarse para desarrollar complejos algoritmos de aprendizaje automático. Sin embargo, es un recurso que está fuera del alcance de la mayoría de las empresas.
La Inteligencia Artificial generativa sigue siendo líder
¿Para qué sirven los datos en todas sus escalas?
El acceso a los macrodatos permite crear modelos de IA y aprendizaje automático más sofisticados y de mejor rendimiento. Pero muchas empresas deben conformarse con conjuntos de datos mucho más pequeños.
Para las empresas más pequeñas y las que operan en sectores tradicionales como la sanidad, la fabricación o la construcción, la falta de datos es el mayor impedimento para aventurarse en la IA.
La brecha digital entre grandes y pequeñas organizaciones de datos es un serio problema debido a los efectos de red de datos que se refuerzan a sí mismos. En esta circunstancia, entre más datos existen, se conducen a mejores herramientas de IA, que ayudan a atraer a más clientes que generan más datos, y así sucesivamente.1
Esto da a las empresas más grandes una fuerte ventaja competitiva de IA, con las organizaciones pequeñas y medianas luchando por mantenerse al día.
La idea de que varias pequeñas empresas pongan en común sus datos en un repositorio central controlado conjuntamente existe desde hace tiempo, pero la preocupación por la privacidad de los datos puede echar por tierra este tipo de iniciativas.2
El aprendizaje automático federado (FedML) es una tecnología innovadora reciente que supera este problema mediante una IA colaborativa que utiliza datos descentralizados.
FedML podría convertirse en un elemento de cambio a la hora de abordar la brecha digital entre empresas con y sin big data y permitir que una mayor parte de la economía aproveche la IA.
Es una tecnología que no sólo suena prometedora en teoría. Ya se ha implantado con éxito en la industria, como detallaremos a continuación. Pero antes, explicaremos cómo funciona.
¿Cómo hacer tu estrategia de ventas utilizando herramientas de Inteligencia Artificial?
Small Data y aprendizaje automático federado
FedML es un enfoque que permite a las organizaciones con datos pequeños entrenar y utilizar modelos sofisticados de aprendizaje automático. La definición de datos pequeños depende de la complejidad del problema que aborde la IA.
En el sector farmacéutico, por ejemplo, tener acceso a un millón de moléculas anotadas para el descubrimiento de fármacos es relativamente poco.. Otros factores a tener en cuenta son la sofisticación de la técnica de aprendizaje automático, que puede ir desde una simple regresión logística a una red neuronal mucho más ávida de datos, así como la precisión necesaria para una aplicación.
En igualdad de condiciones, las organizaciones más pequeñas y las que operan en sectores no digitales tradicionales se enfrentan a desventajas.
Ya se han concebido algunas tácticas y técnicas útiles para ayudar a las empresas que se enfrentan a este problema, como la puesta en común de datos entre empresas.3
Sin embargo, el enfoque centralizado de la puesta en común de datos puede no ser adecuado en varias situaciones, como cuando existen restricciones de transferencia de datos. Del mismo modo, el aprendizaje por transferencia y el aprendizaje autosupervisado son enfoques viables sólo cuando una empresa puede basarse en conocimientos previos de modelos de aprendizaje automático que realizan tareas en dominios relacionados, lo que puede no ser siempre factible.
Datos centralizados, el motor de la IA
FedML puede ser un poderoso instrumento adicional en el conjunto de herramientas de IA de una empresa de small-data y servir como complemento crítico a otras técnicas.
En una configuración de aprendizaje federado, un modelo de aprendizaje automático se entrena en múltiples servidores descentralizados controlados por diferentes organizaciones. Cada uno con sus propios datos locales.
Se comunican con un orquestador central que agrega las actualizaciones individuales del modelo y coordina el proceso de formación. En el caso más sencillo, el objetivo de aprendizaje sería obtener hechos descriptivos básicos de la distribución de datos, como medias o varianzas.
Cada empresa podría, por ejemplo, calcular la tasa media de fallos de un determinado proceso de fabricación en una de sus plantas. Y depsués de eso enviarla al orquestador, que combinaría entonces esas contribuciones individuales.
Los componentes básicos de una estrategia de Inteligencia Artificial
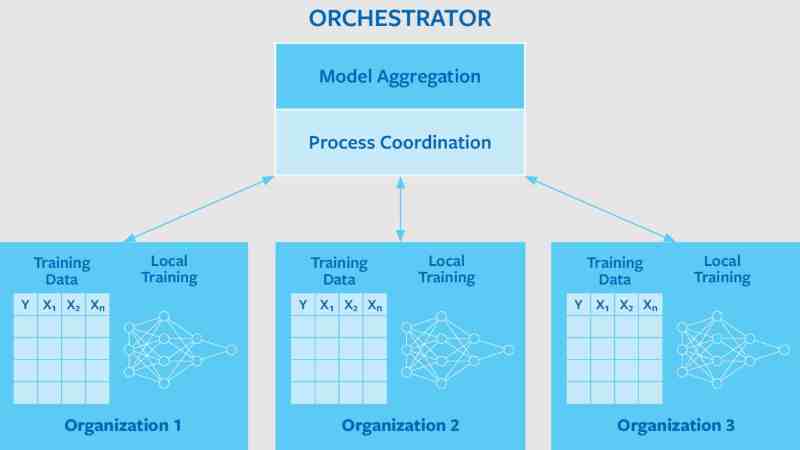
En una configuración de aprendizaje federado, un modelo de aprendizaje automático se entrena en múltiples servidores descentralizados controlados por diferentes organizaciones, cada uno con sus propios datos locales. Se comunican con un orquestador central que agrega las actualizaciones individuales del modelo y coordina el proceso de formación.
¿Qué es FedML y por qué es tan importante para la IA?
FedML es una técnica de aprendizaje automático distribuido que puede utilizarse para diversos algoritmos. Por ejemplo, los pesos o gradientes de una red neuronal pueden promediarse entre organizaciones de forma similar.
El orquestador se encarga de configurar la arquitectura inicial del modelo y de coordinar el proceso de entrenamiento, que suele tener lugar a lo largo de múltiples iteraciones.
Como resultado, las empresas pueden entrenar modelos complejos de aprendizaje automático con un gran número de parámetros que, de otro modo, estarían fuera de su alcance.
Es importante destacar que los datos brutos de las empresas permanecen privados, y sólo los datos estadísticos se comparten y agregan cuando se aplica FedML.
De este modo, 10 pequeñas empresas colaboradoras con datos que tienen acceso a x puntos de datos cada una podrían alcanzar un poder predictivo similar con sus aplicaciones de IA/aprendizaje automático que una empresa mucho mayor con acceso a 10 veces x puntos de datos, sin comprometer la privacidad.
FedML, ¿cómo actúa la IA en la farmacia?
La innovación en el sector farmacéutico es muy costosa y requiere mucho tiempo. En 2022, el coste medio de comercialización de un nuevo fármaco rondaba los 2 mil 300 millones de dólares, y el proceso puede durar más de 10 años.
Una de las principales dificultades del descubrimiento de fármacos radica en el elevadísimo número de moléculas posibles. A esto se le suma el reto asociado de encontrar moléculas con cualidades prometedoras en ese vasto espacio químico.
En un contexto de costos tan elevados y de tantas posibilidades moleculares, los modelos de aprendizaje automático predictivo son la piedra angular del programa de descubrimiento de fármacos impulsado por la IA en el sector farmacéutico.
Las farmacéuticas también se enfrentan a la presión de las grandes empresas tecnológicas, como Alphabet, que utilizan sus profundos conocimientos en IA.
Usa a la Inteligencia Artificial para promover la diversidad en tu empresa
Janssen Pharmaceutica y la IA
Consciente de la reticencia a compartir datos de descubrimiento de fármacos, pero también del gran potencial de la IA colaborativa para impulsar la eficiencia en el descubrimiento de fármacos, Hugo Ceulemans, director científico de Janssen Pharmaceutica, comenzó a proponer la idea de FedML y a entablar conversaciones con sus homólogos en 2016.
Sus esfuerzos finalmente contribuyeron a la formación del consorcio Melloddy por 10 compañías farmacéuticas en 2019.
En una entrada de blog, Ceulemans señaló que, si bien las empresas farmacéuticas habían puesto en común datos anteriormente para respaldar los esfuerzos de predicción.4
Dado que el nuevo consorcio FedML permitiría que las contribuciones de datos subyacentes permanecieran bajo el control de los respectivos propietarios de datos y no se compartieran, sería posible un alcance mucho más ambicioso, explicó.
¿Qué es Melloddy?
Melloddy, término que designa la orquestación de ledgers de aprendizaje automático para el descubrimiento de fármacos, fue un proyecto piloto de tres años destinado a probar la viabilidad y eficacia de FedML.
El proyecto fue cofinanciado por la Unión Europea. La Comisión Europea consideró que Melloddy era un caso de prueba para generar conocimientos para sectores empresariales más allá del farmacéutico.
Entre las empresas participantes se encontraban AstraZeneca, Bayer, GSK, Janssen Pharmaceutica, Merck y Novartis. Estas empresas contaron con el apoyo de socios tecnológicos y académicos, como Owkin y KU Leuven.
Al aprovechar los datos de los demás sin compartirlos realmente, las empresas farmacéuticas participantes pudieron entrenar sus modelos de aprendizaje automático con el mayor conjunto de datos de descubrimiento de fármacos del mundo. Esto permitió realizar predicciones más precisas sobre moléculas prometedoras e impulsó la eficiencia en el proceso de descubrimiento de fármacos.
En una entrada de blog, Mathieu Galtier, jefe de producto de Owkin, explicó que, gracias al uso del aprendizaje federado por parte de Melloddy, los datos nunca salieron de la infraestructura de ninguno de los socios farmacéuticos.
La Inteligencia Artificial de tu empresa, ¿en realidad lo es?
Así se producía el proceso de aprendizaje automático
El proceso de aprendizaje automático se producía localmente en cada empresa farmacéutica participante, y sólo se compartían los modelos.
“Se dedica un importante esfuerzo de investigación a garantizar que sólo se comparte información estadística entre los socios”, escribió.5
Los resultados del proyecto piloto de Melloddy, que concluyó en 2022, revelaron que la creación de una plataforma multipartita segura para la IA colaborativa que utiliza datos descentralizados es factible y que el rendimiento de los modelos de aprendizaje automático mejora realmente utilizando un enfoque FedML.
Consideraciones estratégicas para los consorcios FedML
Al crear un consorcio FedML, quienes participan en el proceso de planificación deben considerar cuidadosamente el enfoque óptimo para orquestar la tecnología e incentivar a los socios.
El orquestador seleccionado asume un papel fundamental en la gestión eficaz del proceso FedML. Los responsables de las pequeñas organizaciones de datos son a veces reacios a asociarse con grandes empresas tecnológicas porque pueden mantener un mayor control estratégico y estrechar lazos con socios tecnológicos más pequeños que operan en pie de igualdad.
Y algunos incluso temen que las propias grandes empresas tecnológicas entren en su sector, como está ocurriendo en el farmacéutico.
En el caso de Melloddy, las farmacéuticas eligieron a Owkin, una startup, para que asumiera la responsabilidad de orquestar la plataforma FedML del consorcio. Este puede ser un buen enfoque para muchas iniciativas FedML, pero puede ser arriesgado, dada la alta tasa de fracaso de las startups:
Riesgos potenciales a los que se enfrentan las empresas de todos los tamaños
Un consorcio podría desmoronarse si la startup fracasa. También existe el riesgo potencial de que la startup consiga financiación de un competidor que no participe en el consorcio. Es una situación incómoda, pero no improbable.
Por lo tanto, si se elige una empresa emergente como principal orquestador tecnológico, los socios del consorcio deberían considerar seriamente la opción de invertir capital riesgo corporativo (CVC, por sus siglas en inglés).6
Cuando los socios tienen una participación conjunta considerable de CVC en la empresa emergente, con derechos de tanteo, tienen un control mucho mayor sobre la duración de la carrera de la empresa emergente tecnológica y su trayectoria futura.
FedML puede dar lugar a un problema de incentivos, en el que algunos participantes no utilicen todos los datos locales relevantes o no inviertan en la infraestructura de datos necesaria para mejorar la precisión de sus modelos locales.
Pueden optar por no hacer el esfuerzo y confiar en las contribuciones de datos realizadas por otros socios del consorcio. Este comportamiento de parasitismo socava la motivación y la participación de los participantes bienintencionados.
Los brujos del mañana con la Inteligencia Artificial
Para evitar este problema, el consorcio FedML puede acordar los compromisos adecuados de los socios en términos de cantidad y cobertura de los datos aportados y especificarlos por adelantado en un acuerdo contractual.
Las actualizaciones locales del modelo también pueden ser supervisadas por el orquestador en función de su contribución a la precisión global del modelo conjunto, y el pago de una cuota de servicio FedML puede ser proporcional a la contribución de cada socio al proceso de aprendizaje federado.
Después de apostar por el FedML, ¿qué se debe de hacer?
Al dar los primeros pasos hacia la creación de un consorcio FedML, es vital conseguir la participación de los socios. Por lo tanto, los socios deben participar en la definición de los objetivos del consorcio a cambio de su compromiso con los datos.
El AI Canvas es una herramienta de toma de decisiones que puede ser útil para identificar y debatir casos de uso de aprendizaje automático y los datos de entrenamiento necesarios.6 Al ponerse en contacto con los socios, tenga en cuenta que las actualizaciones efectivas de los modelos en la mayoría de las aplicaciones FedML requieren acceso a datos locales sobre todas las variables relevantes del modelo.
En consecuencia, los socios adecuados suelen encontrarse dentro del mismo sector, compartiendo procesos empresariales y datos similares. Trabajar con competidores indirectos, como los que sirven a otros mercados geográficos, en lugar de con competidores directos podría ser ventajoso en este caso para minimizar posibles conflictos.
Para las organizaciones de datos pequeñas que se aventuran en FedML, es aconsejable empezar con proyectos de aprendizaje automático alcanzables para establecer el impulso y crear confianza entre los socios antes de embarcarse en proyectos más ambiciosos.
FedML es todavía un enfoque de IA joven, desarrollado en 2016 por un grupo de ingenieros de Google.8 Pero el progreso en este campo es rápido, y podemos esperar un aumento de su adopción en una amplia gama de sectores empresariales. Los líderes con visión de futuro de las organizaciones de pequeños datos que incorporen FedML a sus visiones estratégicas estarán mejor posicionados para aprovechar el poder transformador de la IA para dar forma a su éxito futuro.
SOBRE LOS AUTORES
Yannick Bammens es profesor de estrategia e innovación en la Universidad de Hasselt (Bélgica), donde codirige la iniciativa AI4Business. Paul Hünermund es profesor adjunto de Estrategia e Innovación en la Copenhagen Business School de Dinamarca, donde coorganiza el encuentro anual Causal Data Science.
REFERENCIAS (8)
1. S.S. Levine y D. Jain, “How Network Effects Make AI Smarter“, Harvard Business Review, 14 de marzo de 2023, https://hbr.org.
2. Y. Bammens y P. Hünermund, “How Midsize Companies Can Compete in AI“, Harvard Business Review, 6 de septiembre de 2021, https://hbr.org.
3. R. Ramakrishnan, “How to Build Good AI Solutions When Data Is Scarce“, MIT Sloan Management Review 64, nº 2 (invierno de 2023): 48-53.
4. H. Ceulemans, “Melloddy: una idea audaz puesta en práctica“, 28 de julio de 2020, Melloddy (blog), www.melloddy.eu.
5. M. Galtier, “Melloddy: A ‘Co-Opetitive’ Platform for Machine Learning Across Companies Powered by Owkin Technology“, 17 de febrero de 2020, Melloddy (blog), www.melloddy.eu.
6. Y. Bammens y J. Lilienweiss, “How Tech Startups Protect Against the Downside of Corporate Venture Capital“, Entrepreneur & Innovation Exchange, 2 de diciembre de 2022, https://eiexchange.com.
7. A. Agrawal, J. Gans y A. Goldfarb, “A Simple Tool to Start Making Decisions With the Help of AI“, Harvard Business Review, 17 de abril de 2018, https://hbr.org.
8. H.B. McMahan, E. Moore, D. Ramage, et al., “Communication-Efficient Learning of Deep Networks From Decentralized Data“, Actas de la 20.ª Conferencia Internacional sobre Inteligencia Artificial y Estadística 54 (abril de 2017): 1273-1282.
Te recomendamos Síguenos en Google News
Síguenos en Google News



Yannick Bammens y Paul Hünermund
y recibe contenido exclusivo
